
Data Cleaning for Beginners
Where Do You Start with Data Cleaning?
You’ve just been handed a dataset and told to clean it up before it can be used for reporting, analysis, or migration. There’s just one problem—you’ve never done this before.
Maybe you’re a project manager overseeing an IT system migration, and your team tells you the data needs cleaning before it can be loaded. Maybe you’re a data analyst trying to build a dashboard but keep running into errors because the numbers don’t add up. Or maybe you’re an SAP consultant working on an ERP implementation and hearing phrases like “deduplication,” “data validation,” and “standardisation” for the first time.
At this moment, you likely have a lot of questions:
- What does ‘cleaning data’ actually mean?
- How do I know what needs fixing?
- What’s the right order to follow?
- How do I avoid making the data worse?
If this sounds familiar, you’re in the right place.
What Is Data Cleaning, and Why Does It Matter?
Data cleaning is the process of identifying and fixing problems in data to make it reliable and usable.
Raw data is rarely perfect. It often contains:
✅ Duplicates – The same customer appearing multiple times under slightly different names.
✅ Missing Values – Key information, like an order’s delivery date, is missing.
✅ Inconsistencies – One column records dates as “DD/MM/YYYY”, while another uses “YYYY-MM-DD”.
✅ Errors – Negative prices, incorrect email addresses, or misspelt country names.
If these issues aren’t addressed, they can cause serious problems in an IT project or analytical process:
🚨 Faulty business decisions – Executives rely on reports built on flawed data.
🚨 System failures – An ERP migration crashes because required fields contain invalid data.
🚨 Wasted time and resources – Data scientists spend 80% of their time cleaning data instead of analysing it.
In short, dirty data leads to bad decisions, failed implementations, and frustrated teams.
Why Does the Order of Data Cleaning Matter?
If you’ve never cleaned data before, you might assume that you just start fixing things as you find them. But this can actually make things worse.
Example: Imagine you’re cleaning up a customer database. If you fill in missing values before removing duplicate records, you’ll waste time correcting data that will be deleted later. Similarly, if you try to analyse data before standardising formats, your calculations will be wrong.
Data cleaning is a structured process, and following the right sequence of steps ensures:
✅ You don’t waste time fixing data that will later be removed.
✅ Errors don’t spread into final reports or IT systems.
✅ You avoid introducing new problems while fixing existing ones.
This is why experienced data professionals follow a logical order when cleaning data.
Who Is This Guide For?
This guide is for anyone who has been asked to clean data but doesn’t know where to start.
We will walk you through each step of the process, explain why each step matters, and help you avoid common mistakes that could make things worse.
By the end, you will:
✔ Understand the main stages of data cleaning.
✔ Know which tasks come first and why.
✔ Feel confident in identifying and fixing common data issues.
Let’s get started! 🚀
The Four Main Steps in Data Cleaning
Now that you understand why data cleaning matters and why the order of steps is important, let’s take a high-level look at the four main stages of data cleaning.
Think of this as your roadmap to guide you through the process. Each step serves a distinct purpose, ensuring that by the end, your data is clean, structured, and ready for use.
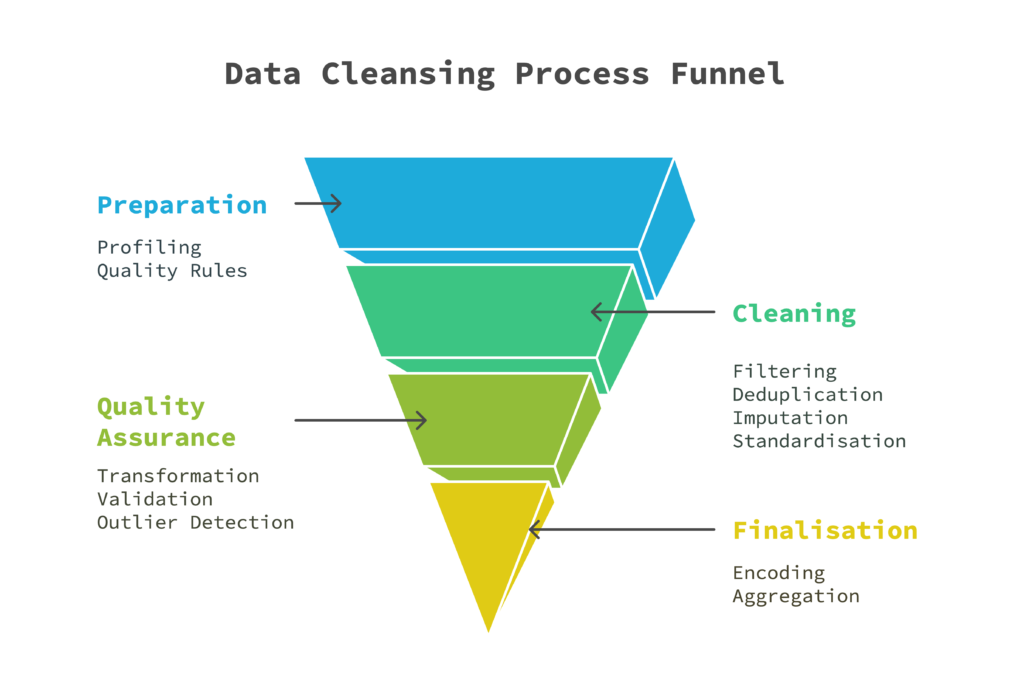
1️⃣ Preparation – Understanding Before Fixing
📌 What is it?
Before making any changes, you need to assess the current state of the data. This means checking for errors, inconsistencies, and missing information so you can create a plan for cleaning it.
📌 Why is it important?
Fixing data without understanding it first is like fixing a car without diagnosing the problem—you could easily make things worse. You don’t want to spend hours filling in missing values only to discover later that half the data should have been removed in the first place.
📌 What happens in this step?
🔹 Profiling – Inspecting the dataset for missing values, duplicates, and unusual patterns.
🔹 Quality Rules – Setting standards for what “good” data should look like before making any changes.
💡 Key takeaway: Before cleaning data, you need to understand what’s wrong with it.
2️⃣ Cleaning – Fixing Errors and Inconsistencies
📌 What is it?
This is where you remove irrelevant data, fix mistakes, and ensure consistency. It’s the most hands-on stage of data cleaning, requiring attention to detail and logical decision-making.
📌 Why is it important?
If errors and inconsistencies aren’t fixed, they will flow into later stages, creating bigger problems. For example, if duplicate customers aren’t removed, reports will double-count sales figures, leading to inflated revenue numbers.
📌 What happens in this step?
🔹 Filtering – Removing test data, outdated records, and irrelevant information.
🔹 Deduplication – Identifying and merging duplicate records.
🔹 Imputation – Filling in missing values carefully, considering potential biases.
🔹 Standardisation – Ensuring formats are consistent across all records (e.g., date formats, currency symbols, measurement units).
💡 Key takeaway: This step ensures that errors are fixed before data is used for analysis or migration.
3️⃣ Quality Assurance – Ensuring Accuracy and Logical Consistency
📌 What is it?
Even after cleaning, there may still be hidden errors or inconsistencies that need to be addressed. This step ensures that all cleaned data follows logical business rules before it’s used in a report, dashboard, or system migration.
📌 Why is it important?
If data is clean but logically incorrect, the impact can be just as bad as having dirty data. Imagine a financial report where some invoices have negative total amounts—this is a clear sign of an error that would undermine business decisions.
📌 What happens in this step?
🔹 Transformation – Restructuring data to fit the intended use (e.g., splitting full names into first and last names).
🔹 Validation – Checking that all values follow logical rules (e.g., ensuring a “shipping date” is never earlier than the “order date”).
🔹 Outlier Detection – Identifying extreme values that could be errors or genuine anomalies.
💡 Key takeaway: Even clean data can contain logical errors—this step ensures everything makes sense.
4️⃣ Finalisation – Preparing Data for Use
📌 What is it?
Once data is cleaned and validated, the final step is to prepare it for its intended purpose—whether that’s a business report, data migration, or machine learning model.
📌 Why is it important?
If data is not formatted correctly, it may still cause system errors or inaccurate analysis. This is the final quality control step before the data is put to use.
📌 What happens in this step?
🔹 Encoding – Converting categorical values into numerical ones for machine learning (e.g., changing “Yes/No” responses to 1/0).
🔹 Aggregation – Summarising and grouping data for reports and dashboards.
💡 Key takeaway: This step ensures the cleaned data is structured correctly for its final use.
Deep Dive: How Causality Shapes the Data Cleaning Process
Now that we’ve covered the four main stages of data cleaning, let’s take a step back and understand why they are structured in this specific order.
If you’re new to data cleaning, it may be tempting to jump straight into fixing errors as soon as you see them. However, this approach often leads to wasted effort, unnecessary rework, and even bigger data issues down the line.
The reason we follow this structured process is causality—each stage of cleaning is designed to fix issues that would interfere with later steps. Think of it as building a house:
🏗️ First, you lay the foundation (Preparation). If you don’t do this, the whole structure will be unstable.
🔨 Then, you put up the walls and framework (Cleaning). But only after making sure the foundation is solid.
🧩 Next, you check that everything is properly connected (Quality Assurance). If the plumbing or wiring is wrong, fixing it later is much harder.
🏠 Finally, you decorate and furnish the house (Finalisation). Doing this before checking the structure would be a disaster.
The same principle applies to data cleaning—you must follow a logical order to ensure that each step prepares the data for the next one.
Why Each Step Group Has a Specific Sequence
Each of the four stages of data cleaning follows a specific internal sequence. Let’s explore why this order matters and how skipping or rearranging steps can cause problems.
1️⃣ Preparation – Understanding Before Fixing
📌 Why this comes first:
Before touching the data, you need to fully understand its current state. Otherwise, you might try fixing the wrong things or spend time on unnecessary tasks.
📌 Why these steps are in this order:
- Data Profiling comes first because you need to identify what’s wrong before attempting any fixes.
- Defining Data Quality Rules follows because, once you understand the issues, you must set standards for what the cleaned data should look like.
📌 What happens if you skip or reorder these steps?
- If you start fixing missing values before profiling, you might spend hours filling in gaps in a dataset that actually contains duplicates—meaning some of those values should be deleted instead of imputed.
- If you don’t define quality rules before starting, you’ll end up making inconsistent fixes—different team members might format dates differently, or apply different thresholds for outlier detection.
💡 Key takeaway: Preparation prevents wasted effort and ensures cleaning is done correctly.
2️⃣ Cleaning – Fixing Errors and Inconsistencies
📌 Why this comes after preparation:
Once you’ve identified problems and set quality rules, you can now fix the data. Cleaning is the most hands-on stage, requiring careful attention to duplicates, missing values, and inconsistencies.
📌 Why these steps are in this order:
- Data Filtering happens first to remove irrelevant data—this prevents fixing data that shouldn’t be there in the first place.
- Data Deduplication follows because duplicates can cause errors in later steps (e.g., missing values might exist in multiple versions of the same record).
- Data Imputation comes next—once unnecessary and duplicate records are gone, you can fill in missing values without duplicating effort.
- Data Standardisation happens last because you need complete data before making formats consistent.
📌 What happens if you skip or reorder these steps?
- If you impute missing values before deduplication, you might be filling in data for records that will later be removed—wasting time.
- If you standardise data before deduplication, two versions of the same record might end up looking identical, making it harder to spot duplicates.
💡 Key takeaway: Errors must be removed first, or they will spread into later steps.
3️⃣ Quality Assurance – Ensuring Accuracy and Logical Consistency
📌 Why this comes after cleaning:
Now that your data is free of obvious errors, it’s time to validate that everything makes sense and follows business logic.
📌 Why these steps are in this order:
- Data Transformation comes first, as restructuring the dataset (e.g., splitting names, merging columns) ensures that the final validation checks apply to the correct data.
- Data Validation follows to check that all values conform to business rules and system requirements.
- Outlier Detection comes last, because validating data first helps determine if extreme values are errors or just unusual but correct data points.
📌 What happens if you skip or reorder these steps?
- If you validate data before transformation, you might be checking fields that will later be changed—meaning you’ll need to validate again.
- If you remove outliers before validating, you might delete valuable but unusual data points that actually make sense in context (e.g., a one-time large purchase).
💡 Key takeaway: Even ‘clean’ data can be incorrect—this step ensures logical consistency.
4️⃣ Finalisation – Preparing Data for Use
📌 Why this comes last:
The final stage prepares data for its intended purpose, ensuring it is correctly formatted for reporting, system migration, or machine learning.
📌 Why these steps are in this order:
- Data Encoding happens first because machine learning models and some systems require numerical input instead of text categories.
- Data Aggregation follows because summarising data before encoding could lead to loss of categorical information.
📌 What happens if you skip or reorder these steps?
- If you aggregate before encoding, you may lose important category details that should have been converted first.
- If you encode too early, debugging errors in categorical data becomes much harder.
💡 Key takeaway: Finalisation ensures cleaned data is correctly structured for use.
The Role of Iteration in Data Cleaning
Although data cleaning follows a logical sequence, iteration is often required. Certain steps might need to be revisited when new issues are discovered.
🔄 Common Iterations in Data Cleaning:
- If outlier detection reveals extreme values due to incorrect imputation, you may need to return to the imputation step and adjust your method.
- If validation shows that certain fields still have errors, you may need to redo standardisation or transformation.
- If profiling uncovers unexpected data patterns, you may need to update your data quality rules and restart some cleaning steps.
💡 Key takeaway: Data cleaning is not always a linear process—new findings may require you to revisit previous steps.
The Power of Causality in Data Cleaning
By following a structured process based on cause and effect, you ensure that each step builds on the previous one, preventing wasted effort and errors.
✅ Preparation ensures you clean the right things.
✅ Cleaning removes errors before structuring the data.
✅ Quality assurance ensures logical consistency.
✅ Finalisation makes sure the data is ready for use.
💡 Skipping steps or doing them out of order can lead to inaccurate reports, system failures, and frustrated stakeholders.
Take the Next Step in Your Data Cleaning Journey
By now, you should have a solid understanding of the data cleaning process, why the sequence of steps matters, and how causality shapes the workflow. If this is your first time handling data cleaning, you might be feeling both informed and slightly overwhelmed—and that’s completely normal!
Data cleaning is a skill that improves with experience. The more you work with real datasets, the more you’ll start recognising patterns in data issues, knowing which fixes work best, and understanding how different decisions impact downstream processes.
So, where do you go from here?
🔹 1. Put Your Knowledge into Action
The best way to learn data cleaning is by doing it. If you’ve been given a dataset to clean, start by following the structured process we discussed:
✅ Profile the data before making any changes.
✅ Fix errors in a logical order to avoid spreading issues.
✅ Validate your cleaned data to make sure it’s correct.
✅ Finalise the data so it’s ready for its intended use.
Even if you’re not working on a project yet, you can practice with open datasets to sharpen your skills. Websites like Kaggle and Data.gov provide real-world datasets that often need cleaning before they can be used effectively.
🔹 2. Download the Quick Guide for Easy Reference
We’ve condensed the core steps of data cleaning into a Quick Help Guide—a practical reference you can use whenever you’re cleaning data.
Keep it handy so you can quickly refer back to the key steps whenever you need a structured approach to cleaning data.
🔹 3. Join the Conversation
Every dataset is unique, and data cleaning often involves problem-solving beyond the basics. Have you encountered an issue that wasn’t covered in this guide? Do you have a specific challenge in your current project?
💬 Drop a comment below and share your experiences!
- What’s the most frustrating data issue you’ve encountered?
- What questions do you still have about data cleaning?
- Do you have any tips or lessons learned from your first data cleaning project?
Data professionals, consultants, and project managers all face different challenges, and learning from each other’s experiences is a great way to level up your skills.
🔹 4. Stay Connected for More Data Best Practices
This is just the beginning of your data journey. We’ll be sharing more insights, best practices, and real-world case studies on topics like:
📌 Common Mistakes in Data Cleaning (and How to Avoid Them)
📌 How to Automate Data Cleaning with Python, SQL, and Excel
📌 Data Governance: Why Clean Data Isn’t Just an IT Problem
➡ Follow this page or subscribe to our newsletter to stay updated!
Data Cleaning is a Superpower
It might not be the most glamorous task, but mastering data cleaning makes you invaluable in any data-driven role. Whether you’re an SAP consultant working on an ERP implementation, a project manager overseeing a system migration, or a data analyst preparing datasets for reporting, clean data is the foundation of success.
So, take what you’ve learned today, apply it to your next project, and start building your expertise in data quality management. You’ve got this! 🚀